동기화 도구
이전 포스팅의 Pererson’s Solution을 보면 이론적으로 완벽하지만 entry section, critical section, exit section에서 사용하는 명령어가 Atomic 하지 않아 기대 결과가 달라졌다.
이는 기계어의 관점에서 또는 저급 언어 수준에서 구현이 되지 않았기 때문인데 이렇게 개발자가 기계어 수준에서까지 개발을 하는 일은 쉬운 일이 아니기에 고급 언어에서 아래와 같은 동기화 도구를 제공한다. 각 동기화 도구에 대해 알아보자.
- Mutex Lock
- Semaphore
- Monitor
Mutex Lock
mutex란 mutual exclusion에서 나온 용어로 상호배제를 목표로 한다.
lock을 acquire(획득)한 프로세스나 스레드만 critical section에 접근이 가능하며, critical section에서 빠져나온 프로세스는 lock을 release(반환)하여 다른 프로세스가 critical section에 진입할 수 있도록 한다.
Mutex Lock의 특징은 acquire()과 relase()라는 두개의 메서드와 Lock이라는 변수로 이루어져 있고 이는 모두 atomic 하다.
아래 구조가 Mutex Lock의 동기화 방식인데 acquire메서드를 보면 available 변수가 존재한다. 이 변수가 Lock이다.
acquire메서드를 보면 while문을 통해 available(락) 값을 compare(비교)하고 임계영역에 들어오면 available (락) 값을 false로 swap(교환) 하는데 과정을 보면 두 명령어이지만 실제 os 수준에서 compare_and_swap이라는 하나의 명령어로 실행된다.

Busy waiting과 Spin Lock의 특징
위의 acquire 메서드의 while문을 보자.
락을 획득하기 위해 쉬지 않고 무한루프를 돈다. 대기하며 쉬지 않기에 Busy waiting이라고 하며
무한루프를 도는 것을 Spin이라고 한다.
그리고 이렇게 spin을 통해 lock을 얻는 방식을 Spin Lock이라고 한다.
1. 싱글 코어 멀티 프로세스 환경에서 치명적 문제
무한루프를 돌기 때문에 의미없는 CPU 점유로 인해 CPU 생산성이 낮아질 수 있다.
2. 멀티코어 멀티 프로세스 환경에서는 장점
무한루프를 도는 동안 컨텍스트 스위칭이 일어나지 않기에 락이 release 됬을 때 빠르게 lock을 획득 할 수 있음
즉, 하나의 코어에서 실행 중인 프로세스에서 락을 획득하여 critical section을 실행 중일 때,
다른 코어의 프로세스들은 쉬지 않고 계속 루프를 돌고 있기에 lock이 반환되었을 때 곧바로 lock을 획득하여 critical section 작업을 수행할 수 있다. 이로인해 spin lock 방식은 주로 lock을 빠르게 반납 가능한 경우에 사용한다.
(wait-notify 방식 같은 경우 대기하는 스레드를 깨워서 ready 큐에 넣은 다음 가져오므로 상대적으로 속도가 느리다.)
[참고] 현대 컴퓨터에서는 spin lock에서도 context-switching 발생함
spin lock은 이론적으로 contexts-switching이 발생하지 않도록 설계 했지만 실제 cpu의 알고리즘에 따라 context-switching이 발생한다. 허나, 이론적 이해를 위해 context-switching이 발생하지 않는다고 하자.
(싱글코어에서 spin lock이 context-switching 발생하지 않으면 무한루프에서 못빠져나옴)
[예제]
아래는 mutex 예제이다. 설명은 위에서 충분히 하였으므로 코드를 실행하여 동시성 문제가 발생하지 않는지 확인해보자.
#include <stdio.h>
#include <pthread.h>
int sum = 0;
pthread_mutex_t mutex;
void *counter(void *param){
int k;
for(k=0; k < 10000; k++) {
// lock acquire
pthread_mutex_lock(&mutex);
// critical section
sum++;
// lock release
pthread_mutex_unlock(&mutex);
}
pthread_exit(0);
}
int main()
{
pthread_t tid1, tid2;
pthread_mutex_init(&mutex, NULL);
pthread_create(&tid1, NULL, counter, NULL);
pthread_create(&tid2, NULL, counter, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("sum = %d\n", sum);
}
Semaphore
Mutex와 마찬가지로 상호배제를 목표로 한다.
P : wait() 과 V : signal() 이라는 두개의 원자적 메서드로 이루어져 있다. (자바에서는 signal()이 notify())
아래 wait과 singal 메서드를 보자.
S는 lock의 갯수를 의미한다. wait을 통해 락 존재 여부를 확인하고 락이 존재하면 락 하나를 획득하고 임계영역에 진입하고 임계영역에 빠져나올때는 signal을 통해 락을 반환한다.

이때 S의 값이 1이라면 락이 하나만 존재한다는 뜻이므로 mutex와 동작 방식이 같다. 이러한 Semaphore를 Binary Semaphore라 한다. S의 값이 1보다 크면 S의 갯수만큼 프로세스가 임계영역에 진입할 수 있다. 이를 Counting Semaphore라고 한다.
Counting Semaphore에서 공유자원에 여러 스레드가 접근하면 동시성 문제가 발생하는 것 아니냐라고 생각할 수 있지만
Semaphore는 주로 공유자원이 여러개일 때 사용한다.
예를 들어 프린터가 3개일 때 3개의 프로세스가 각각의 프린터를 사용하도록 할 수 있다.
Spin Lock을 제거한 Semaphore

위는 Spin Lock이 아닌 스레드를 wait queue에 대기시키는 방식으로 구현한 Semaphore이다.
value값이 Semaphore 갯수가 되고 list가 wait queue에 해당한다.
Mutex의 Spin Lock은 Lock을 빠르게 반환하는 경우에 유리하다. Mutex가 context-switching을 최소화시켜 동기화 처리를 빠르게 진행하는것에 중점을 맞췄다면 Semaphore는 자원 관리에 중점을 맞췄다. 여러 자원을 사용하기에 CPU의 비효율성을 줄이기 위해 프로세스를 대기시키는 방식을 선택한다. CPU의 의미없는 Spin 시간을 줄이고 작업이 지속적으로 이뤄지기 위해 사용하는 것이다.
나 또한 실무에서 Semaphore를 사용한적이 있는데 외부 프로그램을 수행하도록 하는 로직에서 한번에 여러 스레드가 외부 프로그램을 실행시키면 컴퓨터 자원 소모량이 커져 처리속도가 늦어진다거나 심지어는 컴퓨터가 꺼지는 현상까지 발생했다. 이렇게 자원의 효과적인 사용이 필요할 때 Semaphore를 사용하기도 한다.
[예제]
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <stdlib.h> // For malloc and free
#define NUM_THREADS 5
int sum[NUM_THREADS];
sem_t sem;
void *counter(void *param) {
int index = *(int *)param; // 전달받은 인덱스를 사용
for (int k = 0; k < 10000; k++) {
sem_wait(&sem); // P: wait()
// Critical section
sum[index]++;
sem_post(&sem); // V: signal()
}
free(param); // 동적으로 할당한 메모리 해제
pthread_exit(0);
}
int main() {
pthread_t tid[NUM_THREADS];
sem_init(&sem, 0, 1); // 세마포어 초기값을 1로 설정
for (int i = 0; i < NUM_THREADS; i++) {
sum[i] = 0;
int *index = malloc(sizeof(int)); // 동적으로 메모리 할당
if (index == NULL) {
perror("malloc");
exit(EXIT_FAILURE);
}
*index = i; // 각 스레드에 전달할 인덱스 저장
pthread_create(&tid[i], NULL, counter, index); // 스레드 생성
}
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(tid[i], NULL); // 스레드 종료 대기
}
for (int i = 0; i < NUM_THREADS; i++) {
printf("sum[%d] = %d\n", i, sum[i]); // 배열의 각 요소 출력
}
sem_destroy(&sem); // 세마포어 해제
return 0;
}
Monitor
모니터는 동기화 메커니즘에 사용되는 데이터 타입(ADT : Abstract Data Type)으로 Mutual Exclusion(상호배제)와 Cooperation(협력)을 목표로 한다.
Mutual Exclusion은 Monitor-Lock을 통해 구현되며, Cooperation은 wait과 notify, notifyAll 메서드와 Condition Varaible을 통해 구현된다.
wait과 notify 메서드는 자바 Object 클래스에 정의되어 있다. 구현부를 보고 싶었지만 아래와 같이 native 키워드가 적용되어 JVM에 의해 기계어로 실행된다.
public final native void wait(long timeoutMillis) throws InterruptedException;
public final native void notify();
public final native void notifyAll();
모니터의 구조를 보자.
shared data(공유 데이터)가 존재하며 공유 데이터를 조작하는 operations가 존재한다.
operations가 임계영역의 대상이 되는 shared data를 manipulate(조작)하는 명령어들이다.
initialization code는 mutex나 semaphore 예제에서 보았듯이 동기화를 구현하기 위해 초기화하는 코드이다.
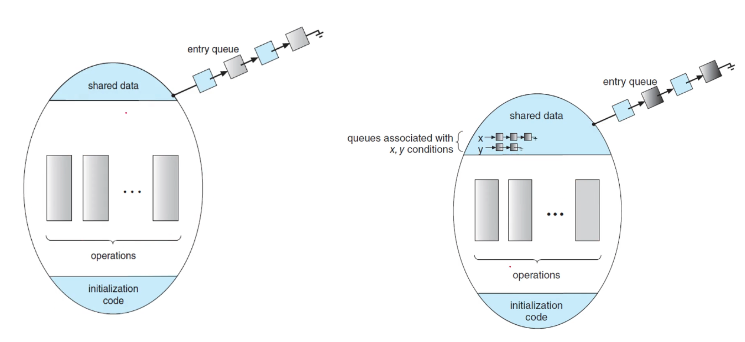
모니터에는 Condition Varaiable이라는 변수도 존재하는데 조건에 따라 스레드를 wait(대기)시키거나 notify(깨우기) 위한 목적이다. 임계영역에 진입하려는 스레드가 Condition Variable의 조건을 만족하지 못하면 스스로 wait을 호출하여 wait queue에 가서 대기한다. 그리고 이미 임계영역에 진입한 스레드는 빠져나오기 전 Condition Variable을 만족하면 wait queue의 스레드를 notify(깨우기)한다.
즉, 스레드들이 스스로 협력하며 공유 자원을 관리하는 것이다. 따라서 우리는 이를 Coopertion(협력)이라고 한다.
Lock이 있음에도 Condition Variable을 사용하는 이유는 Lock을 반환할 때 스레드를 깨우면 wait queue에서 ready queue로 스레드를 이동시키는 과정으로 인해 스레드 진입 속도가 늦어지기 때문에 미리 스레드를 깨워 경쟁상황을 만들어 빠르게 다음 스레드가 임계영역에 진입시키기 위한 목적이다.
이전에 설명한 Mutex의 Spin Lock의 장점을 취하고 Semaphore의 단점을 상쇄시킨 방식이다.
Condition Varaible이 여러개 존재하면 더 다양한 조건에서 wait과 notify를 활용하겠지만 자바에서는 Condition Variable을 하나만 사용한다.
Synchronized 키워드
자바의 mutex lock 메커니즘을 제공해주는 키워드이다.
Synchronized에서 사용되는 lock은 monitor-lock 또는 intrinsic lock(암시적 락)이라고 하며 자바 객체에 내장된 락이다.
Synchronized 키워드를 적용하면 entry section code나 exit section code가 JVM에 의해 적용된다.
'OS & Network > OS' 카테고리의 다른 글
| 동시성 문제[1] - 동시성 문제의 원인과 해결법 (0) | 2024.07.28 |
|---|---|
| 프로세스[2] - 멀티 프로세스와 멀티 스레드 (0) | 2024.07.25 |
| 프로세스[1] - 프로세스란, PCB와 Context Switch (0) | 2024.07.25 |
| 메모리[2] - 페이징, 가상메모리 (0) | 2024.07.25 |
| 메모리[1] - 메모리 주소 할당 (0) | 2024.07.20 |



