[용어 정리] 객체지향 프로그래밍을 이해하기 위해 필요한 아래의 용어에 대해 먼저 설명하겠다.
모듈
모듈이란 프로그램을 구성하는 기능 단위의 독립적인 명령어들의 집합이다.
모듈은 독립적이며 유일한 기능을 갖고 다른 프로그램이나 모듈에서 호출되어 재사용될 수 있어야한다.
따라서 모듈은 다양한 형태로 존재할 수 있는데 메서드, 객체, 패키지, 라이브러리 등이 이에 해당한다.
(상위 모듈 : 호출하는 모듈 / 하위 모듈 : 호출 당하는 모듈)
의존
의존이란 모듈(또는 객체 등)이 동작하기 위해 다른 모듈의 자원을 사용하는 상황을 의미한다.
이는 호출 당하는 하위 모듈의 변경사항이 호출하는 상위 모듈에 영향을 미친다는 것을 의미한다.
의존성
의존성의 존재 여부는 호출되는 하위 모듈의 변경사항이 호출하는 상위 모듈에 영향을 미치는지 여부로 판단할 수 있다.
의존성에는 방향이 존재하고 호출하는 모듈이 호출당하는 모듈을 의존한다고 표현하며 방향성은 아래와 같이 나타낼 수 있다.
상위모듈 -> 하위 모듈
결합도
모듈간의 의존성의 정도를 비교하는 용어
낮은 결합도 vs 높은 결합도 (느슨한 결합 vs 강한 결합)
결합도가 낮다는 것은 의존 객체 또는 의존 객체에서 사용하는 자원이 적다는 것을 의미한다.
단순히 의존객체의 수나 의존 객체의 메서드 수, 속성의 수로 판단하는 것 뿐만 아니라
추상화에 의존하는지, 구현부에 의존하는지에 따라서도 결합도의 높고 낮음을 판단할 수 있다.
결합도는 낮을수록 좋다
결합도를 낮추게 되면 의존하는 객체의 변경사항에 영향을 적게 받을 수 있다.
캡슐화를 통해 영향을 미치는 자원의 수를 줄일 수 있고,
인터페이스 타입 의존을 통해 추상 메서드에만 의존하면 구현부 변경의 영향도를 줄일 수 있다.
응집도
모듈의 내부 요소들이 하나의 기능 수행을 위해 얼마나 밀접하게 관련되어있는지를 나태는 용어
높은 응집도 vs 낮은 응집도
높은 응집도란 한 모듈 내의 구성 요소들이 하나의 기능을 수행하기 위해 밀접하게 관련되어 있는 상황을 말한다.
반대로 낮은 응집도란 하나의 기능 수행을 위한 요소가 여러 모듈에 흩어져 있는 경우나 한 모듈 내에 여러 기능 수행을 위한 요소들이 섞여 있는 경우이다.
응집도는 높을수록 좋다.
하나의 기능 수행을 위해 필요한 구성요소들만 모듈에 존재해야 코드 파악이 쉬워져 유지보수에 용이하다.
여러 기능 수행을 위해 많은 구성요소들이 모듈 내에 존재한다면 코드 파악이 어려워 유지보수에 어려움을 겪을 수 있다.
또한 하나의 기능 수행을 위한 구성요소들이 여러 모듈에 걸쳐져 있는 경우에도 코드 파악에 어려움을 겪고
이는 결합도 또한 증가시켜 의존 모듈의 변경사항에 민감한 구조를 갖추게 한다.
※ 응집도를 높이는 코드 구현의 tip
만일 class A에 a, b, c, d, e, f라는 속성이 있고
특정 기능을 수행하기 위해 a, b, c 라는 속성이 연관되어 사용되고,
또 다른 기능을 수행하기 위해 d, e, f 라는 속성이 연관되어 사용된다고 할 때,
(a, b, c)와 (d, e, f)는 서로 연관도가 떨어지기에 이런 경우에는 a, b, c를 갖는 속성과 d, e, f를 갖는 속성의 클래스를 분리 시키는 것이 응집도를 높이는데에 좋다.
클린코드라는 책에 나온 내용을 적어봤다.
클래스에 여러 메서드들이 있을 때, 각 메서드들에서 사용되는 인스턴스 변수나 인자값들을 비교해보고 연관성이 떨어진다면새로운 클래스로 분리하는 하나의 방법론으로 소개된 내용이다.
객체 지향 프로그래밍(OOP)이란?
객체에 책임과 역할을 부여하고 다른 객체에 책임이 전파되는 것을 최소화(중복 제거)하며 객체 간의 협력을 통해 시스템을 만드는 것을 지향하는 프로그래밍 방식. 즉, 고유한 책임을 가진 객체들 간의 협력으로 시스템을 구성
- 객체가 문제 해결과 설계의 기본 단위로 객체 관점에서 프로그래밍 한다.
- 절차지향에 비해서 사람의 사고방식과 더 가깝다.
- 시스템에 필요한 처리를 독립적이고 고유한 객체(모듈)에 집중화할 수 있다.
(이는 특정 처리 로직이 분산되지 않고 한곳에 집중되어 코드 추적의 용이함을 가져다 준다.)
OOP에서 객체의 특징
- 객체의 책임은 교집합이 있을 수 없다
객체는 자신의 책임을 완벽하게 수행해야하며 이를 통해 높은 응집도를 얻을 수 있다.
이는 기능에 대한 처리를 하나의 객체에 집중시켜 코드 중복을 제거하고 코드 가독성을 향상 시킬 수 있다. - 객체는 내부와 외부로 구분된다
객체의 외부는 다른 객체와 소통하기 위한 정보인 메서드이며 내부는 객체의 속성이나 구현부를 말한다.
OOP는 객체들의 협력 구조로 이루어져있기에 협력을 위한 소통 수단과 객체가 갖고 있는 책임 영역을 구분하기 위함이다.
객체의 외부인 소통 수단의 범위를 줄여 결합도를 낮추고 내부영역의 책임을 강화하여 응집도를 높일 수 있다.
- 객체는 자신의 상태(속성)를 스스로 관리한다
객체의 속성변경은 객체가 제공하는 수정자 메서드를 통해서만 이뤄져야한다.
객체의 속성을 private 으로 선언하고 수정자 메서드를 통해서만 속성 변경이 이뤄지도록 하여 객체의 속성 변경 조건을 직접 제어하고 추적의 용이함을 얻을 수 있다. - 객체는 책임과 역할을 부여 받는다.
- 객체는 상태(속성)와 행위(메서드)를 갖는다.
- 객체는 유기적으로 협력하며 협력은 메서드를 통해 이루어진다.
OOP의 4가지 특징
1. 추상화(Abstration)
구체적인 사물들 간의 공통점(핵심)을 취하고 차이점은 배제하는 일반화이다.
자바에서는 인터페이스나 추상클래스와 같은 추상 자료형을 제공한다.
이 자료형을 통해 객체들의 공통적인 부분을 추출하여 협력구조를 갖추게 한다면 시스템을 단순하고 유연하게 만들 수 있다.
[추상화의 예시]
재판을 하는 왕과 여왕, 목격자인 토끼, 증언을 하는 상인, 요리사, 앨리스가 있다고 하자.
재판을 하는 상황을 따져보면 아래와 같이 많은 상황이 나타난다.

이를 프로그래밍을 통해 구현하게된다면 모두 독립적으로 각각의 케이스를 구현하게 될 것이다.
그러나 이를 추상화를 통해 공통적인 것을 추출하고 차이점은 배제한다면
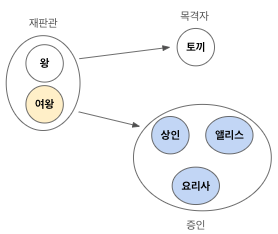
위와 같은 구조로 단순화 할 수 있다.
재판관의 역할, 목격자의 역할, 증인의 역할로 공통점을 추출하였고 각 객체들이 하는 구체적인 행위는 배제하였다.
왕과 여왕이 갖는 재판의 책임을 재판관이라는 역할로 추상화화였고, 상인, 앨리스, 요리사가 갖는 증언을 하는 책임을 증인이라는 역할로 추상화하였다.
객체들은 고유한 책임을 갖고 있다고 했다.
이 책임들의 공통점을 추출하여 하나의 집합으로 표현한 것이 역할이다.
프로그래밍 코드로 설명을 하면 인터페이스가 역할에 해당하고, 구현클래스가 책임을 갖는다고 생각하면 된다.
역할은 책임을 규명할 수 있기에 인터페이스는 구현 클래스가 가져야할 책임을 정의할 수 있다.
추상화의 장점
- 단순함 : 추상화를 통해 복잡한 시스템을 단순화하고 이를 통해 코드 추적에 용이함과 유지보수에 용이함을 얻을 수 있다.
- 유연성 : 책임을 갖는 구현체가 변경되더다도 객체들의 협력 구조는 변하지 않는다.
- 기능 확장과 변경에 용이 : 원래 구조에서 새로운 책임을 갖는 객체를 조립하듯 끼워넣어 사용할 수 있다.
추상화의 단점
- 복잡성 증가 : 지나친 추상화는 시스템을 직관적으로 파악하기 어렵게 만듦
- 구현의 어려움 : 변동이 많은 비즈니스의 경우 추상화 적용이 쉽지 않음
2. 상속(Inheritance)
부모 클래스의 속성과 행위를 하위 클래스에 복제하고 확장하는 개념이다.
상속의 주된 사용 목적은 계층 구조 표현과 코드 재사용이다.
계층 구조를 만들어 확장성 있는 시스템을 만들 수 있고, 코드 재사용을 통해 코드 중복을 제거할 수 있다.
다만, 상속은 컴파일 타임에 코드가 묶여 캡슐화가 깨지는 높은 결합도를 유발하기에 사용에 주의해야한다.
하위 타입에서 어떤 부분에 대해 오버라이딩 해야하는지 명확한 정의를 내리지 않는다면 상속 가능한 구조로 설계하는 것은 바람직하지 않다.
상속의 장점
- 코드 재사용 : 상위 클래스의 속성가 기능을 그대로 물려 받기에 중복제거를 통한 코드 재사용을 이룰 수 있다.
- 변경과 확장의 용이함 : 공통된 사항이 상위 클래스에 정의되어있기에 상위 클래스 변경사항을 하위 클래스에 전파 시킬 수 있고(단점이 될 수 있음), 추상 메서드를 통한 하위 구현체에서 기능 확장이 용이함
상속의 단점
- 강한 결합 : 캡슐화가 지켜지지 않기에 상위 클래스의 변경사항이 하위 클래스에 많은 영향을 미친다.
- 클래스 폭발
- 단일 상속
상속에 대한 더욱 자세한 특징은 이 포스팅이 아닌 아래 포스팅에서 더욱 깊이있게 다루도록 하겠다.
3. 다형성
하나의 객체가 여러 타입을 가질 수 있다. (또는 하나의 타입에 여러 객체가 대입될 수 있다.)
다형성을 좀 더 쉽게 표현하면 하나의 객체가 다양한 형태(타입)를 가질 수 있다는 것이다.
1) 오버라이딩(객체 수준의 다형성)
부모 클래스의 메서드를 자식 클래스에서 재정의하여 사용하는 것을 의미
[오버라이딩의 예시]
좀전의 추상화에서 들었던 예시를 코드로 표현하겠다.
증인이라는 역할은 진술을 하는 것이다.
따라서 아래와 같이 Witness라는 인터페이스의 state(증언)라는 행위를 할 수 있어야한다.
interface Witness {
String state();
}
그리고 각 책임을 가진 상인, 요리사, 앨리스는 자신이 알고 있는 증언을 해야한다.
public class Merchant implements Witness {
@Override
public String state() {
return "친구와 이야기를 하고 있었어요";
}
}
public class Chef implements Witness {
@Override
public String state() {
return "저는 스프를 조리하고 있었어요";
}
}
public class Allice implements Witness {
@Override
public String state() {
return "난 아무것도 몰라요";
}
}
위와 같이 진술이라는 행위에 대하여 각 구현체들이 다양한 동작을 수행할 수 있다.
이뿐만 아니라 다형성은 다형성을 가진 객체를 사용하는 부분에서도 특징을 갖는다.
아래는 재판관이 재판을 수행하며 증인에게 증언을 하라고 시키는 코드이다.
public class King implements Judge {
private final Witness witness;
public King(Witness witness) {
this.witness = witness;
}
@Override
public void conductTrial() {
// 증인에게 증언하라고 시킴
String statement = witness.state();
}
}
재판관인 왕은 증인이라는 것만 알고 있으며 증인의 진술은 증인에 따라 다양하게 나타날 수 있다.
Judge judge = new King(new Allice());
// King king = new King(new Chef());
// King king = new King(new Merchant());
// 재판관이 재판을 실시함
judge.conductTrial();
Witness 타입은 요리사, 상인, 앨리스를 모두 받아낼 수 있으므로 King 생성자에 주입될 때 업캐스팅을 통해
다양한 구현체를 받아 conductTrial에서 다양한 진술이 나올 수 있게 되는 것이다.
다형성은 오버라이딩을 통해 다양하게 실현될 수 있으며 사용하는 곳에서는 구체적인 구현체의 타입을 알지 못해도
다양한 행위의 결과를 받을 수 있는 것이다.
변수나 메서드 인자값에 상위 타입으로 선언하여 다양한 하위 타입 구현체를 처리하는 확장성 있는 구조를 갖추게 한다.
오버라이딩은 주로 인터페이스 구현이나 추상 클래스 상속에서 나타나는 기법이므로 상속이 갖는 장점과 비슷하다.
* 오버라이딩 제약 사항
- 메서드의 접근 지정자는 부모 클래스 보다 좁게 지정할 수 없다.
- 메서드 예외 타입은 부모 클래스보다 넓게 지정할 수 없다.
2) 오버로딩(메서드 수준의 다형성)
같은 이름의 메서드에 대해 메서드의 인자값의 타입과 갯수, 순서를 다르게 정의하여 사용하는 것
(순서를 다르게 할 경우 타입도 달라야함, 리턴값, 접근지정자는 포함 안됨)
[오버로딩 예시]
아래는 오버로딩의 예시이다.
public class AdditionProcessor {
public int add(int a, int b) {
return a + b;
}
public int add(int a, int b, int c) {
return add(a, b) + c;
}
public long add(int a, int b, int c, Long d) {
return add(a, b, c) + d;
}
}
오버로딩은 가독성을 위해 또는 호출자가 편리하게 사용하기 위해 적용한다.
위에서 보는 것과 같이 add라는 메서드는 모두 더하기 연산을 한다. 기대동작이 모두 같다.
이와 같이 유사한 기대 동작을 하고 인자값에 따른 특정한 처리만 추가적으로 하게 되는 경우 오버로딩을 적용하면
처리를 집중화할 수 있고 가독성 또한 얻을 수 있다.
오버로딩의 가장 큰 목적은 호출 객체에서 단순하게 사용하기 위한 것(가독성)이다.
4. 캡슐화(Encapsulation)
객체의 속성과 행위를 하나의 캡슐로 만들어 외부의 접근으로부터 보호하는 개념이다.
캡슐화는 구체적인 내용은 감추고 객체들간의 협력을 위한 부분만 노출하여 객체의 변경사항이 다른 객체에 미치는 영향을 최소화하는 장점을 가져다 준다. (낮은 결합도)
[캡슐화 예제]
아래와 같은 Car 클래스가 있다고 하자.
public class Car {
public Engine engine;
public Battery battery;
public void boostEngine(){
engine.start();
}
public void batteryOn() {
battery.on();
}
}
위 클래스는 속성과 행위과 모두 public으로 열려있다.
위와 같은 코드의 단점은 객체가 생성되고 나서 아무런 제약조건 없이 배터리가 바뀔수 있다는 것이다.
Car car = new Car(engine, battery);
// ...
car.battery = newBattery;
우리 자동차를 배터리 수명이 다한 경우에만 배터리를 교체할 수 있도록 정책을 정했다고 하더라도
사용하는 곳에서 제대로 사용하지 못하면 의도하지 않은 동작이 발생할 수 있다는 것이다.
따라서 아래와 같이 private 접근지정자를 통해 외부에서 배터리에 직접 접근하는 것을 막고,
수정자 메서드인 changeBattery를 만들어 배터리 수명이 다한 경우에만 속성을 수정할 수 있도록 제한하여 의도하지 않는 동작을 막을 수 있다.
private Engine engine;
private Battery battery;
public void changeBattery() {
if (battery.lifeEnd()) {
this.battery = new Battery();
}
}
또한 여기서 캡슐화를 진행할 수 있는 부분이 한 곳 더 있다.
public void boostEngine() {
engine.start();
}
public void batteryOn() {
battery.on();
}
두 메서드는 모두 public으로 열려 있는데
자동차의 시동을 걸기 위해서 우리는 아래와 같이 코드를 실행해야한다.
car.batteryOn();
car.boostEngine();
예제에서는 배터리를 켜는것과 엔진을 점화 시키는 것 두가지 뿐이지만
실제 자동차에 시동을 걸때 이뤄지는 작업은 이보다 훨씬 많을 것이다.
따라서 아래와 같이 캡슐화를 진행하였다.
private void boostEngine() {
engine.start();
}
private void batteryOn() {
battery.on();
}
public void start() {
batteryOn();
boostEngine();
}
배터리 켜는 것과 엔진 점화를 모두 private으로 막고 start라는 메서드를 통해 모든 동작이 이뤄지도록 하였다.
이러한 방식으로 캡슐화를 진행하게 되면 엔진이나 배터리의 변경으로 인한 영향도를 줄일 수 있다.
만일 우리의 자동차가 엔진 없이 배터리로만 움직이는 자동차로 변경되더라도 엔진을 점화시키는 행위에 대한 의존에서 벗어났으므로
시동을 켜는데 아무런 영향을 미치지 않는다.
캡슐화의 장점
- 낮은 결합도 : 속성과 구현부를 숨겨 모듈간의 의존하는 자원을 줄여 변경사항에 영향을 덜 받는 구조를 만들 수 있다.
캡슐화의 단점
- 비유연성 : 캡슐화 대상 속성이 추후 접근 또는 수정이 가능해야하는 경우, 코드 변경이 어려울 수 있다.
정리
OOP의 장점
- 단순한 구조를 통해 시스템 파악 용이, 유지보수 용이
- 추상화를 통해 복잡한 구조를 하나의 구조로 단순화 가능
- 상속을 통한 계층 구조는 공통 부분과 구체 부분을 분리하여 파악 가능 - 높은 응집도
- 객체에 고유한 책임을 부여함으로써 응집도를 높일 수 있다.
-> 코드 가독성 향상, 변경사항 발생시 코드 수정 범위 최소화 - 낮은 결합도
- 추상화를 통해 인터페이스에 의존하게 하면 구현부가 아닌 소통 수단인 메서드에만 의존하게 할 수 있다.
- 캡슐화를 통해 의존하는 자원의 수를 줄여 결합도를 낮출 수 있다.
OOP의 단점
- 설계의 어려움
OOP의 가장 큰 장점인 추상화나 상속을 잘못 설계한 경우 더 큰 변경사항을 초래할 수 있다. - 복잡성 추가
- 과도한 추상화는 개발자로 하여금 오히려 구조 파악을 어렵게 할 수 있다.
- 너무 깊거나 복잡한 계층 구조는 오히려 구조 파악을 어렵게 할 수 있다. - 캡슐화를 과도하게 사용하면 외부에서 필요한 데이터나 메서드에 접근하기 어렵다.
실제 개발을 하며 특정 메서드의 변경만 필요해 상속을 통해 오버라이딩으로 개발하고자 했으나
해당 메서드가 private이라 새롭게 구현했던 적이 있음
(해당 클래스가 라이브러리에서 제공되는 코드라 접근 지정자 변경 불가)
'Language > 자바&코틀린' 카테고리의 다른 글
| [I/O 이해하기-3] 톰캣의 요청 수신 방식 (0) | 2025.01.27 |
|---|---|
| Garbage Collection의 동작 방식과 종류 (0) | 2024.07.06 |
| [I/O 이해하기-2] Stream vs Channel (0) | 2024.05.09 |
| [I/O 이해하기-1] 동기와 비동기 VS Blocking과 Non Blocking (0) | 2024.05.05 |
| 코틀린 querydsl, mapstruct 생성자에 따른 동작 방식 (0) | 2024.03.16 |



